-
Última Versión
Screaming Frog 20.2 ÚLTIMO
-
Revisado por
-
Sistema Operativo
Windows Vista / Windows 7 / Windows 8 / Windows 10 / Windows 11
-
Ránking Usuario
Haga clic para votar -
Autor / Producto
-
Nombre de Fichero
ScreamingFrogSEOSpider-20.2.exe
Screaming Frog SEO Spider es un rastreador de sitios web que le permite rastrear las URL de los sitios web y obtener elementos clave para analizar y auditar el SEO técnico y en el sitio. Descargue de forma gratuita o adquiera una licencia para funciones avanzadas adicionales.
La aplicación SEO Spider es un rastreador de sitios potente y flexible, capaz de rastrear sitios web pequeños y muy grandes de manera eficiente, mientras que le permite analizar los resultados en tiempo real. Reúne datos clave en el sitio para permitir que los SEO tomen decisiones informadas.
¿Qué puedes hacer con el software SEO Spider?
Encontrar enlaces rotos
Rastrea un sitio web al instante y encuentra enlaces rotos (404s) y errores del servidor. Exportación masiva de errores y URL de origen para corregir o enviar a un desarrollador.
Auditorías redireccionadas
Encuentre redirecciones temporales y permanentes, identifique cadenas de redirección y bucles, o cargue una lista de URL para auditar en una migración de sitio.
Analizar títulos de página y metadatos
Analice los títulos de las páginas y las meta descripciones durante un rastreo e identifique aquellas que son demasiado largas, cortas, faltantes o duplicadas en su sitio.
Descubrir contenido duplicado
Descubra direcciones URL duplicadas exactas con una comprobación algorítmica md5, elementos parcialmente duplicados como títulos de página, descripciones o encabezados y busque páginas de bajo contenido.
Extraer datos con XPath
Recopile todos los datos del HTML de una página web mediante CSS Path, XPath o regex. ¡Esto podría incluir metaetiquetas sociales, encabezados adicionales, precios, SKU o más!
Revisión de robots y directivas
Ver las URL bloqueadas por robots.txt, meta robots o directivas X-Robots-Tag como "noindex" o "nofollow", así como canonicals y rel = "next" y rel = "prev".
Generar XML Sitemaps
Con Screaming Frog puede crear rápidamente Sitemaps XML e Sitemaps Image XML, con configuración avanzada sobre URL para incluir, última modificación, prioridad y cambio de frecuencia.
Integrar con Google Analytics
Conéctese a la API de Google Analytics y obtenga datos del usuario, como sesiones o tasa de rebote y conversiones, objetivos, transacciones e ingresos para las páginas de destino contra el rastreo.
Rastrear sitios web de JavaScript
Realice páginas web utilizando Chromium WRS integrado para rastrear sitios web y marcos dinámicos y ricos en JavaScript, como Angular, React y Vue.js.
Visualizar la arquitectura del sitio
Evalúe el enlace interno y la estructura de URL mediante el rastreo interactivo y diagramas dirigidos a la fuerza de directorios y visualizaciones de sitios de gráficos de árboles.
Características y destacados
El Screaming Frog es una herramienta de auditoría de SEO, construida por SEO reales con miles de usuarios en todo el mundo. Un resumen rápido de algunos de los datos recopilados en un rastreo incluye:
La aplicación SEO Spider es un rastreador de sitios potente y flexible, capaz de rastrear sitios web pequeños y muy grandes de manera eficiente, mientras que le permite analizar los resultados en tiempo real. Reúne datos clave en el sitio para permitir que los SEO tomen decisiones informadas.
¿Qué puedes hacer con el software SEO Spider?
Encontrar enlaces rotos
Rastrea un sitio web al instante y encuentra enlaces rotos (404s) y errores del servidor. Exportación masiva de errores y URL de origen para corregir o enviar a un desarrollador.
Auditorías redireccionadas
Encuentre redirecciones temporales y permanentes, identifique cadenas de redirección y bucles, o cargue una lista de URL para auditar en una migración de sitio.
Analizar títulos de página y metadatos
Analice los títulos de las páginas y las meta descripciones durante un rastreo e identifique aquellas que son demasiado largas, cortas, faltantes o duplicadas en su sitio.
Descubrir contenido duplicado
Descubra direcciones URL duplicadas exactas con una comprobación algorítmica md5, elementos parcialmente duplicados como títulos de página, descripciones o encabezados y busque páginas de bajo contenido.
Extraer datos con XPath
Recopile todos los datos del HTML de una página web mediante CSS Path, XPath o regex. ¡Esto podría incluir metaetiquetas sociales, encabezados adicionales, precios, SKU o más!
Revisión de robots y directivas
Ver las URL bloqueadas por robots.txt, meta robots o directivas X-Robots-Tag como "noindex" o "nofollow", así como canonicals y rel = "next" y rel = "prev".
Generar XML Sitemaps
Con Screaming Frog puede crear rápidamente Sitemaps XML e Sitemaps Image XML, con configuración avanzada sobre URL para incluir, última modificación, prioridad y cambio de frecuencia.
Integrar con Google Analytics
Conéctese a la API de Google Analytics y obtenga datos del usuario, como sesiones o tasa de rebote y conversiones, objetivos, transacciones e ingresos para las páginas de destino contra el rastreo.
Rastrear sitios web de JavaScript
Realice páginas web utilizando Chromium WRS integrado para rastrear sitios web y marcos dinámicos y ricos en JavaScript, como Angular, React y Vue.js.
Visualizar la arquitectura del sitio
Evalúe el enlace interno y la estructura de URL mediante el rastreo interactivo y diagramas dirigidos a la fuerza de directorios y visualizaciones de sitios de gráficos de árboles.
Características y destacados
- Encuentra enlaces rotos, errores y redirecciones
- Analizar títulos de página y metadatos
- Revisión Meta Robots y Directivas
- Auditar hreflang Atributos
- Descubrir páginas duplicadas
- Generar XML Sitemaps
- Visualizaciones del sitio
- Límite de rastreo
- Programación
- Configuración de rastreo
- Guardar rastreos y volver a subir
- Búsqueda de código fuente personalizado
- Extracción personalizada
- Integración de Google Analytics
- Integración de la consola de búsqueda
- Integración de métricas de enlace
- Rendering (JavaScript)
- Robots.txt personalizado
- Rastreo y Validación de AMP
- Validación y datos estructurados
- Almacenar y ver HTML sin procesar y renderizado
El Screaming Frog es una herramienta de auditoría de SEO, construida por SEO reales con miles de usuarios en todo el mundo. Un resumen rápido de algunos de los datos recopilados en un rastreo incluye:
- Errores: errores del cliente, como enlaces rotos y errores del servidor (sin respuestas, 4XX, 5XX).
- Redirecciones: redirecciones permanentes y temporales (respuestas 3XX) y redirecciones JS.
- URL bloqueadas: ver y auditar las URL no permitidas por el protocolo robots.txt.
- Recursos bloqueados: vea y audite los recursos bloqueados en el modo de representación.
- Enlaces externos: todos los enlaces externos y sus códigos de estado.
- Protocolo: si las URL son seguras (HTTPS) o inseguras (HTTP).
- Problemas de URI: caracteres no ASCII, guiones bajos, caracteres en mayúscula, parámetros o URL largas.
- Páginas duplicadas: la comprobación algorítmica del valor de hash / MD5checksums para páginas duplicadas exactas.
- Títulos de página: faltantes, duplicados, más de 65 caracteres, corto, truncamiento de ancho de píxel, igual que h1, o múltiple.
- Meta Descripción: falta, duplicado, más de 156 caracteres, corto, truncamiento de ancho de píxel o múltiple.
- Meta Keywords: Principalmente como referencia, ya que no son utilizadas por Google, Bing o Yahoo.
- Tamaño del archivo: tamaño de las URL e imágenes.
- Tiempo de respuesta.
- Encabezado de última modificación.
- Profundidad de la página (arrastre).
- El recuento de palabras.
- H1 - Falta, duplicado, más de 70 caracteres, múltiple.
- H2 - Falta, duplicado, más de 70 caracteres, múltiple.
- Meta Robots: indexar, noindex, follow, nofollow, noarchive, nosnippet, noodp, noydir, etc.
- Meta Refresh - Incluyendo la página de destino y el retraso de tiempo.
- Elemento de enlace canónico y encabezados HTTP canónicos.
- X-Robots-Tag.
- Paginación - rel = "next" y rel = "prev".
- Seguir y no seguir: a nivel de página y enlace (verdadero / falso).
- Redirigir cadenas: descubre cadenas y bucles de redireccionamiento.
- Atributos de hreflang: audita los enlaces de confirmación, códigos de idiomas incoherentes e incorrectos, hreflang no canónico y más.
- AJAX: seleccione esta opción para obedecer el esquema de rastreo AJAX, actualmente en desuso, de Google.
-
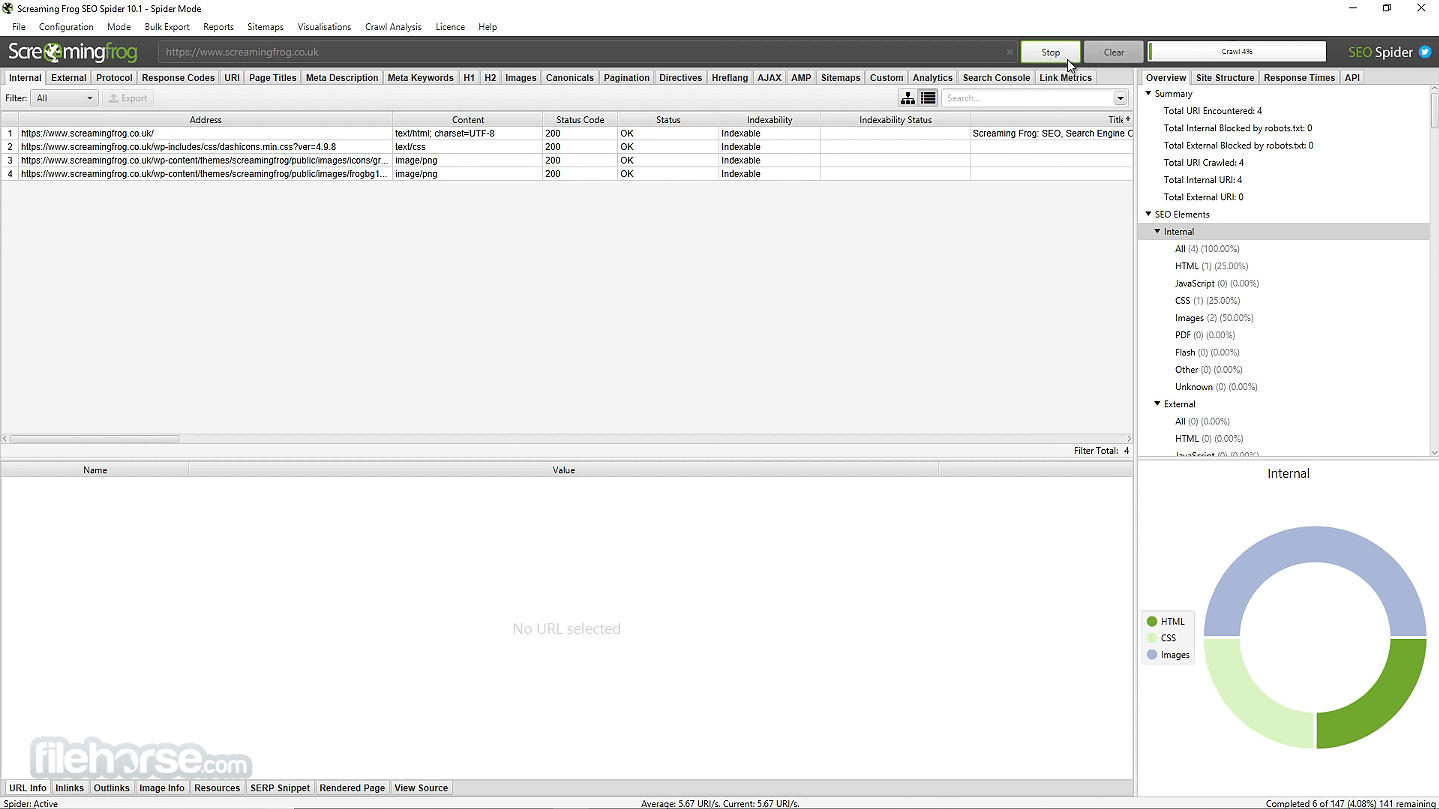
Screaming Frog 20.2 Capturas de Pantalla
Las imágenes a continuación han sido redimensionadas. Haga clic en ellos para ver las capturas de pantalla en tamaño completo.
-

-

-

-

 OperaOpera 112.0 Build 5197.30 (64-bit)
OperaOpera 112.0 Build 5197.30 (64-bit) 4K Download4K Video Downloader+ 1.8.0 (64-bit)
4K Download4K Video Downloader+ 1.8.0 (64-bit) PhotoshopAdobe Photoshop CC 2024 25.11 (64-bit)
PhotoshopAdobe Photoshop CC 2024 25.11 (64-bit) PC RepairPC Repair 1.0.3
PC RepairPC Repair 1.0.3 Opera GXOpera GX 111.0.5168.99 (64-bit)
Opera GXOpera GX 111.0.5168.99 (64-bit) Adobe AcrobatAdobe Acrobat Pro 2024.002.20965
Adobe AcrobatAdobe Acrobat Pro 2024.002.20965 BlueStacksBlueStacks - Play on PC 5.21.300
BlueStacksBlueStacks - Play on PC 5.21.300 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game Trade IdeasTrade Ideas - AI Stock Trading Signals
Trade IdeasTrade Ideas - AI Stock Trading Signals AnyRecoverAnyRecover 6.3.2
AnyRecoverAnyRecover 6.3.2
Comentarios y Críticas de Usuarios