-
Latest Version
PostgreSQL 18.4 LATEST
-
Review by
-
Operating System
Windows 7 64 / Windows 8 64 / Windows 10 64 / Windows 11
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-18.4-1-windows-x64.exe
PostgreSQL is a powerful, open-source object-relational database system. It has more than 15 years of active development and a proven architecture that has earned it a strong reputation for reliability, data integrity, and correctness.
It runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, macOS, Solaris, Tru64), and Windows. PostgreSQL is a powerful object-relational database management system! Download PostgreSQL Offline Installer Setup 64bit for PC!
It is fully ACID compliant, has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages). It includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP.
It also supports storage of binary large objects, including pictures, sounds, or video. It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation (table sizes can go up to 32 TB).
PostgreSQL 2026 comes with many features aimed to help developers build applications, administrators to protect data integrity and build fault-tolerant environments, and help you manage your data no matter how big or small the dataset. In addition to being free and open-source, the tool is highly extensible.
For example, you can define your own data types, build out custom functions, even write code from different programming languages without recompiling your database!
The app tries to conform with the SQL standard where such conformance does not contradict traditional features or could lead to poor architectural decisions.
Many of the features required by the SQL standard are supported, though sometimes with slightly differing syntax or function. Further moves towards conformance can be expected over time.
Features and Highlights
Data Types
OS: Windows 11 or Windows 10 (64-bit)
Processor: Intel or AMD 64-bit processor
RAM: Minimum 2GB, recommended 4GB or more
Storage: At least 100MB for installation, more for data
Additional: Microsoft Visual C++ Redistributable required
PROS
It runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, macOS, Solaris, Tru64), and Windows. PostgreSQL is a powerful object-relational database management system! Download PostgreSQL Offline Installer Setup 64bit for PC!
It is fully ACID compliant, has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages). It includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP.
It also supports storage of binary large objects, including pictures, sounds, or video. It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation (table sizes can go up to 32 TB).
PostgreSQL 2026 comes with many features aimed to help developers build applications, administrators to protect data integrity and build fault-tolerant environments, and help you manage your data no matter how big or small the dataset. In addition to being free and open-source, the tool is highly extensible.
For example, you can define your own data types, build out custom functions, even write code from different programming languages without recompiling your database!
The app tries to conform with the SQL standard where such conformance does not contradict traditional features or could lead to poor architectural decisions.
Many of the features required by the SQL standard are supported, though sometimes with slightly differing syntax or function. Further moves towards conformance can be expected over time.
Features and Highlights
Data Types
- Primitives: Integer, Numeric, String, Boolean
- Structured: Date/Time, Array, Range, UUID
- Document: JSON/JSONB, XML, Key-value (Hstore)
- Geometry: Point, Line, Circle, Polygon
- Customizations: Composite, Custom Types
- UNIQUE, NOT NULL
- Primary Keys
- Foreign Keys
- Exclusion Constraints
- Explicit Locks, Advisory Locks
- Indexing: B-tree, Multicolumn, Expressions, Partial
- Advanced Indexing: GiST, SP-Gist, KNN Gist, GIN, BRIN, Covering indexes, Bloom filters
- Sophisticated query planner/optimizer, index-only scans, multicolumn statistics
- Transactions, Nested Transactions (via savepoints)
- Multi-Version Concurrency Control (MVCC)
- Parallelization of reading queries and building B-tree indexes
- Table partitioning
- All transaction isolation levels defined in the SQL standard, including Serializable
- Just-in-time (JIT) compilation of expressions
- Write-ahead Logging (WAL)
- Replication: Asynchronous, Synchronous, Logical
- Point-in-time-recovery (PITR), active standbys
- Tablespaces
- Authentication: GSSAPI, SSPI, LDAP, SCRAM-SHA-256, Certificate, and more
- Robust access-control system
- Column and row-level security
- Stored functions and procedures
- Procedural Languages: PL/PGSQL, Perl, Python (and many more)
- Foreign data wrappers: connect to other databases or streams with a standard SQL interface
- Many extensions that provide additional functionality, including PostGIS
- Support for international character sets, e.g. through ICU collations
- Full-text search
- Download and install this program from the official site or FileHorse.com
- Open pgAdmin or use the command line for database management
- Create a new database using the pgAdmin interface
- Use SQL queries to create, read, update, and delete data
- Configure user roles and permissions for security
- Backup and restore databases with pgAdmin or command line
- Optimize performance using indexing and query tuning
- Connect applications using PostgreSQL-compatible drivers
- Monitor database activity with built-in logging tools
- Keep PostgreSQL updated for security and performance
OS: Windows 11 or Windows 10 (64-bit)
Processor: Intel or AMD 64-bit processor
RAM: Minimum 2GB, recommended 4GB or more
Storage: At least 100MB for installation, more for data
Additional: Microsoft Visual C++ Redistributable required
PROS
- Open-source and free to use
- Advanced security features
- High scalability and performance
- Supports complex queries and indexing
- Strong community and documentation
- Requires manual performance tuning
- Higher memory usage in some cases
- Limited built-in GUI management tools
- Upgrades may require manual adjustments
Why is this app published on FileHorse? (More info)
-
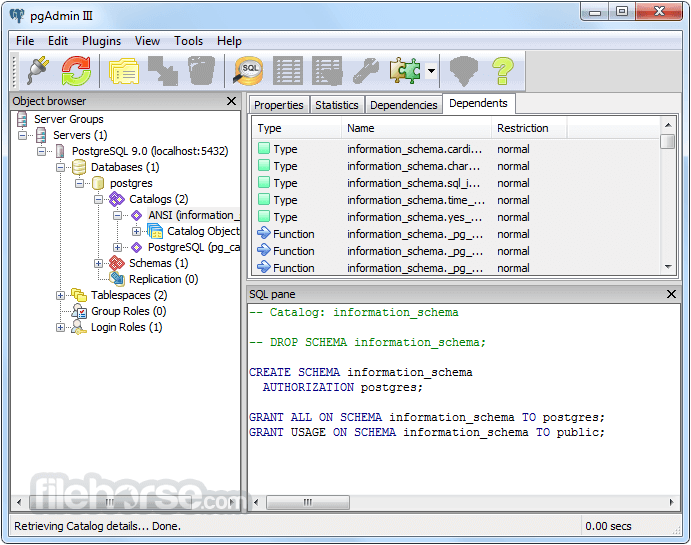
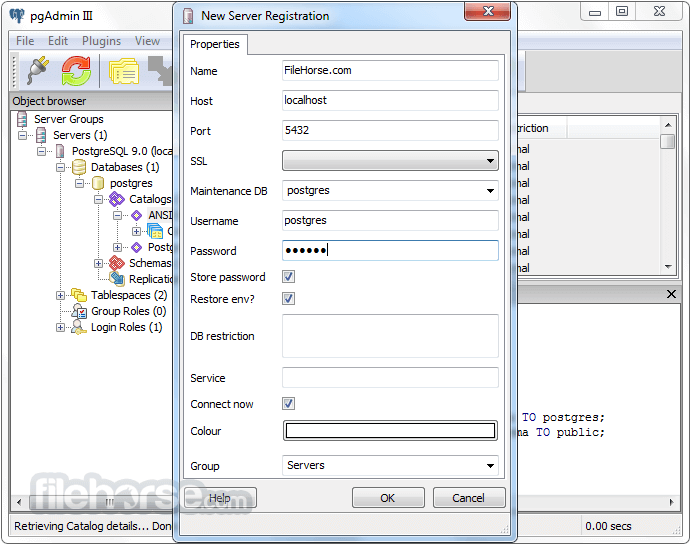
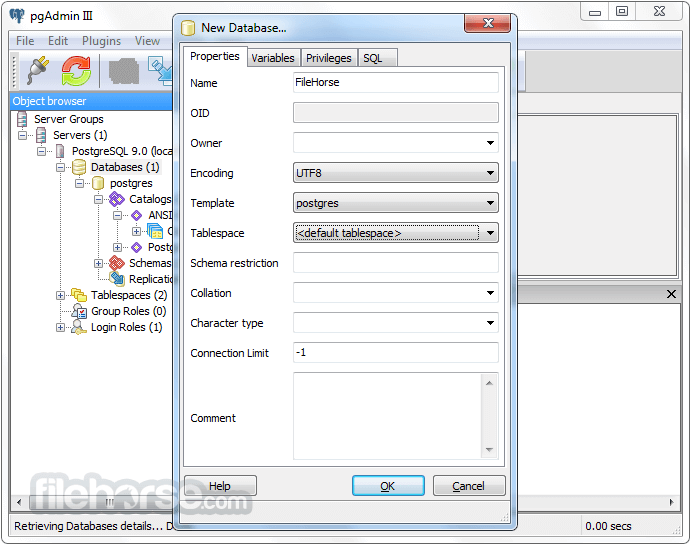
PostgreSQL 18.4 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
-
-
-

-

 OperaOpera 132.0 Build 5905.73 (64-bit)
OperaOpera 132.0 Build 5905.73 (64-bit) LDPlayerLDPlayer - Android Emulator
LDPlayerLDPlayer - Android Emulator PhotoshopAdobe Photoshop CC 2026 27.7 (64-bit)
PhotoshopAdobe Photoshop CC 2026 27.7 (64-bit) BlueStacks AIBlueStacks AI
BlueStacks AIBlueStacks AI NitradoNitrado - Rent a Gaming Server
NitradoNitrado - Rent a Gaming Server CapCutCapCut Desktop 8.7.0
CapCutCapCut Desktop 8.7.0 PC RepairPC Repair Tool 2026
PC RepairPC Repair Tool 2026 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game TradingViewTradingView - Trusted by 100 Million Traders
TradingViewTradingView - Trusted by 100 Million Traders Forza HorizonForza Horizon 6
Forza HorizonForza Horizon 6
Comments and User Reviews